「CS231n Course 4」卷积神经网络
Part 0 前言
参考资料:
Part 1 卷积神经网络概述
卷积神经网络(Convolutional Neural Network, CNN)和上一章中讲述的神经网络非常相似:由神经元组成,神经元中有具有学习能力的权重和偏差。每个神经元得到一些输入,进行内积运算(dot product)再进行激活函数运算。整个网络依旧是一个可导的评分函数:该函数的输入是原始的图像像素,输出是不同类别的评分。再最后一层(往往是全连接层),网络依旧有一个损失函数(如SVM或Softmax),并且在神经网络中实现的各种技巧和要点依旧适用于卷积神经网络。
CNN和NN相比的变化
CNN的结构基于一个假设:输入数据是图像。基于该假设,CNN向结构中添加了一些特有的性质,使得前向传播函数(forward function)更加高效,并且可以大幅降低网络中参数的数量。
结构概述
回顾:常规神经网络(Regular Neural Network但不是RNN)
在上一章中,神经网络的输入是一个向量,然后在一系列隐层中对其做变换。其中,每个隐层是由若干神经元组成的,每个神经元都与前一层中的所有神经元连接(全连接)。但是在一个隐层中,神经元相互独立而不进行任何连接。最后的全连接层被称为”输出层“,在分类问题中,输出值被看作是不同类别的评分值。
常规神经网络对于大尺寸图像的效果不尽如人意
观察常规神经网络的工作,其将图像(如CIFAR10中的 $32 \times 32 \times 3$ ,表示宽和高为 $32$ 个像素,$3$ 个颜色通道)展开为一个列向量,那么每一个全连接神经元就包含 $32 \times 32 \times 3=3072$ 个权重,这个数量级目前看来还好。但是如果图像尺寸更大,如 $200 \times 200 \times 3$ ,那么神经元就会包含 $200 \times 200 \times 3=120,000$ 个权重值,而网络中不止包含一个神经元,所以网络的参数量会快速膨胀。由此也可以发现,全连接结构不适合更大尺寸的图像,这种全连接的方式效率低下,参数量过大也很快会导致网络过拟合。
神经元的三维排列
CNN针对输入全部是图像的情况,将结构调整地更加合理,获得了不小的优势。
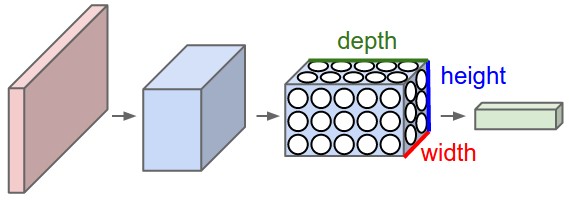
与常规神经网络不同,CNN中的各层的神经元是3维排列的:宽度、高度和深度(此处的深度是指激活数据体(activation volume)的三个维度,不是神经网络的深度,整个网络的深度指的是网络的层数)。
举例而言,CIFAR-10中的图像是CNN的输入,该数据体(volume)的维度是 $32 \times 32 \times 3$ (宽度7高度和深度)。可以看到,层中的神经元只与前一层中的一小块区域连接,而非全连接,因为在CNN的最后部分会将全尺寸的图像压缩为包含分类评分的一个向量,向量是在深度方向排列的。
e.g.
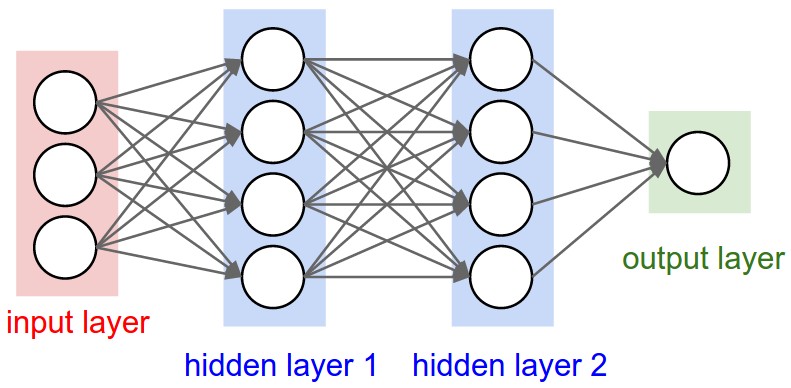
|
|
左边是一个 $3$ 层的神经网络;右边是一个CNN,其神经元以 $3$ 个维度(宽度、高度、深度)进行排列。CNN的每一层将 $3$ 维的输入数据(3D input volume)变化为神经元 $3$ 维的激活数据(3D output volume of neuron activations)并输出。在本例中,红色的输入层就是图像,因此其宽度和高度就是图像的尺寸(dimensions of the image),而深度是 $3$ (RGB通道)。
CNN是由层组成的,每一层都有一个简单的API:用一些含参或者不含参的可导的函数,将输入的3D数据变换为3D的输出数据
Part 2 构建CNN的层
CNN是由各种层按照顺序排列组成的,网络中的每个层使用一个可微分的函数将激活数据从一个层传递到另一个层。
CNN中主要有三种层:卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully-Connected Layer)(全连接层和常规NN中的一样)。
通过这些层的叠加,就可以构建一个完整的CNN。
网络结构示例:[输入层-卷积层-ReLU层-全连接层]([INPUT-CONV-ReLU-POOL-FC])
输入 $[32 \times 32 \times 3]$ 存有图像的原始像素值,本例中图像宽度和高度为 $32$ ,有 $3$ 个颜色通道
卷积层中,神经元和输入层的一个局部区域项链,每个神经元都计算自己与输入层相连的小区域与自己权重的内积。卷积层会计算所有神经元的输出。如果使用12个卷积核(filter,也叫滤波器),得到的输出数据体的维度是 $[32 \times 32 \times 12]$ 。
笔者注:这里应该是使用了零填充(zero pad),因此卷积核没有将输入的维度压缩
ReLU层会逐个元素进行激活函数操作,如使用 $max(0,x)$ 作为激活函数。该层不改变数据尺寸,仍是 $[32 \times 32 \times 12]$。
池化层在空间维度(宽度和高度)进行降采样(downsampling),降低了数据尺寸到 $[16 \times 16 \times 12]$。
全连接层计算分类评分,数据尺寸变为 $[1 \times 1 \times 10]$,这 $10$ 个数字对应 CIFAR-10 中 $10$ 个类别的分类评分值。和常规神经网络中的一样,其中每个神经元与前一层中所有神经元相连接。
由此看来,CNN一层层地将图像从原始像素值变换成最终的分类评分制。其中有的层含有参数,有的没有,具体地:
- 卷积层和全连接层对输入执行变换操作时,不仅会用到激活函数,还会用到很多参数(神经元的突触权值和偏差)。
- ReLU层和池化层则是进行一个固定不变的函数操作,没有参数或者权值更新。
卷积层和全连接层中的参数会随着梯度下降而被训练,这样CNN计算出的分类评分就能和训练集中的每个图像的标签相吻合。
小结
- 上述的简单CNN中,就是通过一系列的层将输入数据变换为输出数据(如分类评分)
- CNN结构中有几种不同的类型(目前流行的有卷积层、全连接层、ReLU层和池化层)
- 每个层的输入是 3D 数据,然后使用一个可导的函数将其变换为 3D 的输出数据
- 有的层有参数,有的没有(卷积层和全连接层有参数,ReLU层和池化层没有)
- 有的层有额外的超参数,有的没有(卷积层、全连接层和池化层有,ReLU层没有)
一个CNN激活输出demo:
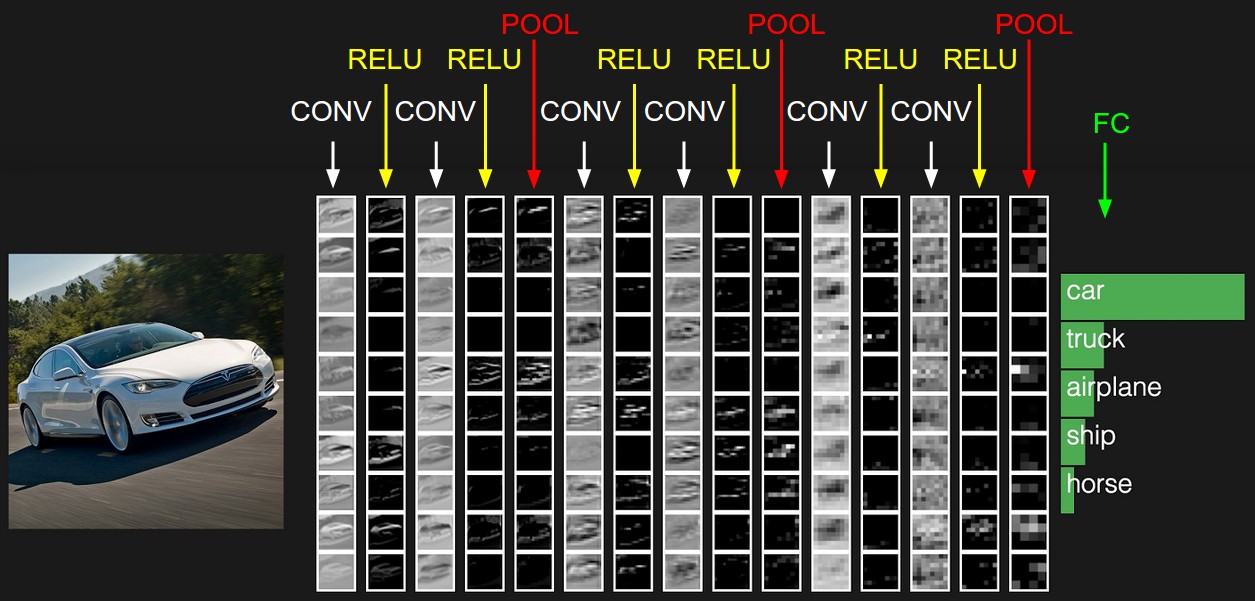
在这个例子中,左边的输入层存有原始图像像素,右边的输出层存有类别分类评分。在处理流程中,每个激活数据体是铺成一列来展示的。
卷积层
卷积层是构建CNN的核心层,它产生了网络中大部分的计算量。
概述和直观介绍
卷积层的参数是由一些可学习的(learnable)卷积核的集合构成的。每个卷积核(filter)在空间上(宽度和高度,width and height)都比较小,但是深度和输入数据一致。
举例来说,CNN第一层的一个典型卷积核的尺寸可以是 $5 \times 5 \times 3$ (宽度和高度是 $5$ 像素,深度是 $3$ 是因为图像的深度是 $3$,即颜色通道)。在前向传播(forward pass)的时候,让每个卷积核在输入数据的宽度和高度上滑动(更精确地说是卷积(convolve)),然后计算卷积核和输入数据任一处的内积。当卷积核沿着输入数据的宽度和高度滑过后,会生成一个 2 维 的激活图(activation map),激活图给出了每个空间位置处的卷积核的反应(response)。直观地说,网络会让卷积核学习到当其看到某些类型的视觉特征时就激活,具体的视觉特征可能是某些方位上的边界,或者在第一层上某些颜色的半点,甚至可以是网络更高层上的蜂巢状或者车轮状图案。
在每个卷积层上,会有一整个集合的卷积核(如 $12$ 个),每个都会生成一个不同的二维激活图($2$ D activation map)。将这些激活映射在深度方向上层叠起来就生成了输出数据。
以大脑比喻的视角
输出的 3D 数据中的每个数据项可以被看作是神经元的一个输出,而这个神经元只观察输入数据的一小部分,并且和空间上左右两边的所有神经元共享参数(因为这些数字都是使用同一个卷积核得到的结果)。现在讨论神经元的连接、他们在空间中的排列以及他们参数共享的模式。
局部连接
处理图像这类高纬度输入时,让每个神经元都与前一层中的所有神经元进行全连接是不现实的。相反,我们让每个神经元只与输入数据的一个局部区域连接,该连接(connectivity)的空间大小叫做神经元的感受野(receptive field),它的尺寸是一个超参数(其实就是卷积核的空间尺寸)。在深度方向上,这个连接的大小总是和输入量的深度相等。
再次强调,我们对待空间维度(宽和高)与深度维度是不同的:连接在空间(宽和高)上是局部的,但是在深度上总是和输入数据的深度一致。
e.g.1
假设输入数据的尺寸是 $[32 \times 32 \times 3]$ (如CIFAR-10的RGB图像);如果感受野(或卷积核尺寸)是 $5 \times 5$ ,那么卷积层中的每个每个神经元会有输入数据体中 $[5 \times 5 \times 3]$ 区域的权重,共 $5 \times 5 \times 3=75$ 个权重(还要再加一个偏差参数 bias parameter)。这个连接在深度维度上的大小必须为 $3$ ,这是和输入数据体的深度保持一致。
e.g.2
假设输入数据体的尺寸是 $[16 \times 16 \times 20]$,感受野尺寸是 $3 \times 3$,那么卷积层中每个神经元和输入数据体有 $3\times 3\times 20=180$ 个连接。
在空间上连接是局部的,但是在深度上是和输入数据体一致的
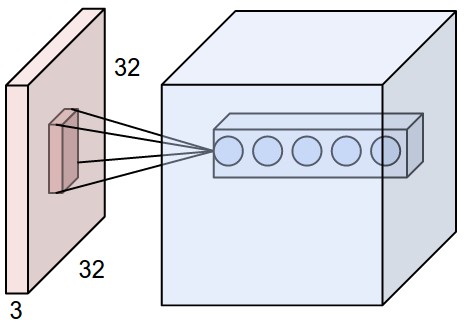
|
|
- 左边:红色的是输入数据体(如CIFAR-10中的图像),蓝色的部分是第一个卷积层中的神经元。卷积层中的每个神经元都只与输入数据体的一个局部在空间上相连,但是与输入数据体的所有深度维度全部相连(在这个例子中,是RGB三个颜色通道)。在深度方向上,有多个神经元(本例中是 $5$ 个),他们都接收输入数据的同一块区域(感受野相同)。
- 右边:神经网络章节中介绍的神经元保持不变,仍计算权重和输入的内积,然后进行激活函数运算。区别在于,卷积层的连接被限制在一个局部空间。
空间排列
接下来讨论输出数据体中神经元的数量以及它们的排列方式。有 $3$ 个超参数控制输出数据体的尺寸:深度(depth)、步长(stride)和零填充(zero-padding)
深度(depth)。输出数据体的深度是一个超参数,其和使用的卷积核数量一致,而每个卷积核在输入数据中寻找不同的东西。举例来说,如果第一个卷积层的输入是原始图像,那么在深度维度上的不同神经元将可能被不同方向的边界(various oriented edges),或者是颜色斑点(blobs of color)激活。
步长(stride)。其次,在滑动卷积核时,必须指定步长。当步长为 $1$ 时,卷积核每次移动 $1$ 个像素。当步长为 $2$ (或不常用的 $3$,这在实际中很少使用),卷积核每次滑动时移动 $2$ 个像素。这个操作会让输出数据体在空间上变小。
选择步长时,应当保证可以卷积核可以正好移动覆盖完。
零填充(zero-padding)。有时候,我们不希望出现数据体尺寸变小的情况,因此可以使用零填充。零填充就是指在输入数据体的边缘用 $0$ 填充,其尺寸是一个超参数。零填充可以控制输出数据体的空间尺寸(最常用的是用来保持输入数据体在空间上的尺寸,这样输入和输出的宽高相等)
输出数据体在空间上的尺寸可以通过数据体尺寸(W),卷积层中神经元的感受野尺寸(F),步长(S)和零填充的数量(P)的函数来计算
This is copyright.